
What is database Connection Pooling and why do we need it? 🤔

Before we jump into that, let’s talk about TCP connections.
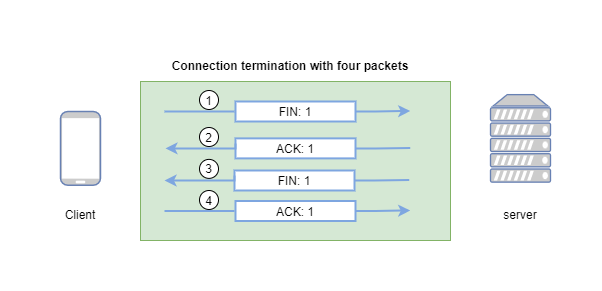
Whenever we establish a TCP connection with a DB server we need to do a 3-way handshake with the server and once we complete the specific operation in our DB then in order to terminate the connection we need to perform a 4-way handshake connection.
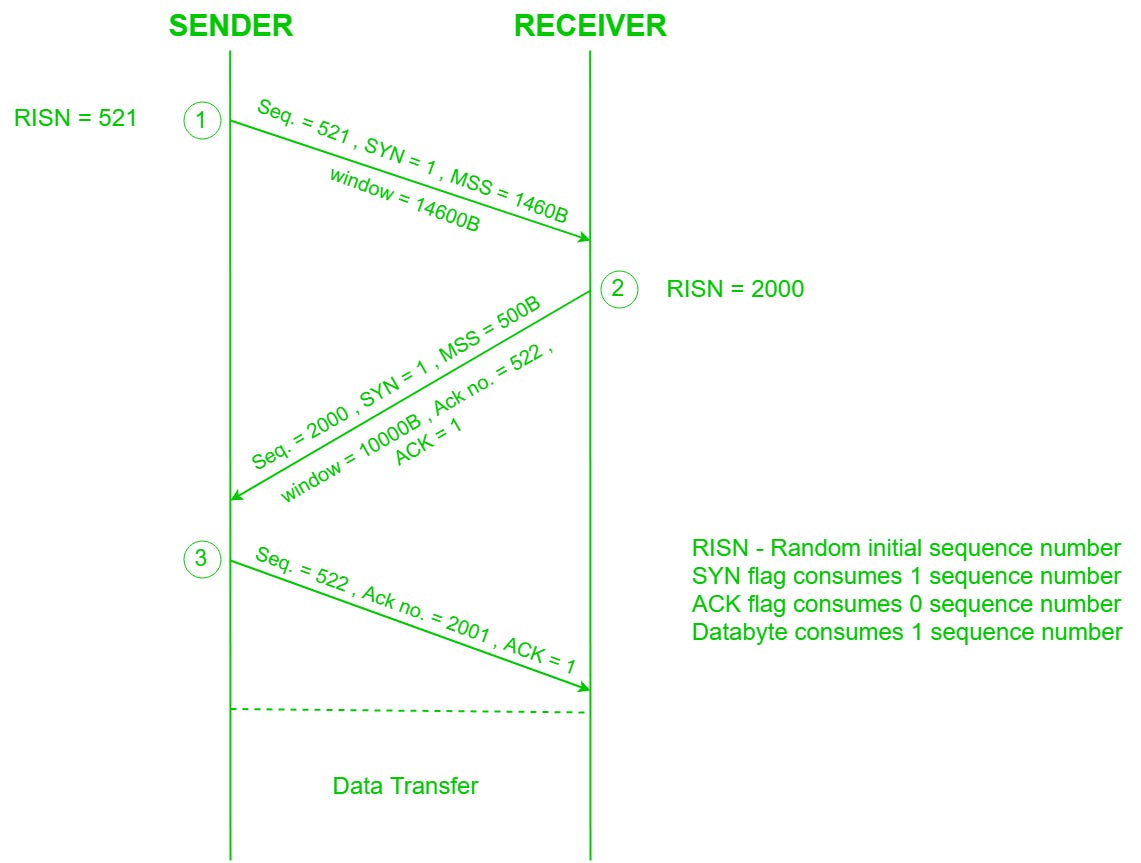
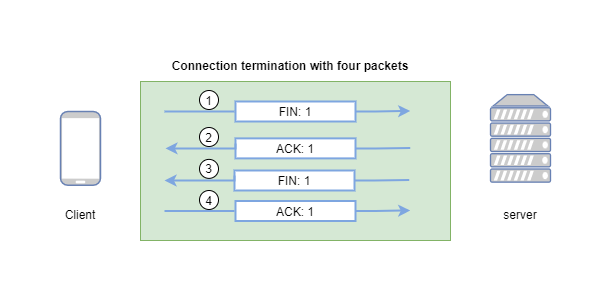
Now for the above operation, in well-optimized and low-latency networks, the round trip time may be in the range of a few milliseconds. However, in networks with higher latency or over longer distances, the RTT can be tens or hundreds of milliseconds.
For example:
Establishing a TCP Connection (Three-Way Handshake)
Typically, it takes 1.5 times the Round Trip Time (RTT).
Examples:
* Same Geographic Location (15ms RTT) — around 22.5ms
* Trans-continental (80ms RTT) — around 120ms
* Inter-continental (150ms RTT) — around 225ms
* Satellite (500ms RTT) — around 750ms
Terminating a TCP Connection (Four-Way Handshake):
Generally takes around 2 times the Round Trip Time (RTT).
Examples:
* Same Geographic Location (15ms RTT) — around 30ms
* Trans-continental (80ms RTT) — around 160ms
* Inter-continental (150ms RTT) — around 300ms
* Satellite (500ms RTT) — around 1000ms
Now let’s say we are doing a simple read/write operation in the DB via your application “x”. Now let’s say we have 1,00,000 requests per second, even though the read/write operation is very minuscule, the cost of establishing the TCP connection is high as it consumes lots of network I/O bandwidth, and not to mention the buffer management, state management, and resource cleanup the OS has to do for each connection.
So now, for 1,00,000 requests/second, we need to establish 1,00,000 TCP connections/second. For this many operations, the expense is high in terms of network I/O and OS operations, so we end up consuming resources for other operations, so our application might choke.
That’s when connection pooling comes into place.
What is connection pooling?
Database Connection Pooling is like having a ready-to-use collection of connections to a database. Instead of creating a new connection every time an app needs to interact with the database, it grabs one from the pool, and when done, it puts it back for others to use. This saves time and effort compared to repeatedly opening and closing connections. It’s like carpooling for database connections, making things more efficient, especially when dealing with a lot of database requests.
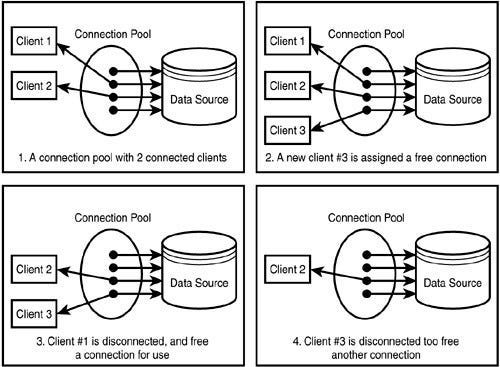
When to use connection pooling?
Generally, it is advised always to leverage connection pooling to utilize the resources better and pave the way to build an efficient system
Please feel free to share your thoughts in the comments. Your input is appreciated!
References:
{kind=link}
{kind=link}
{kind=link}